
Case Study
Multi-User Automotive Data Platform
Problem: Multiple teams worked on shared data within the same platform, but the system had no concept of shared state or readiness. Also ownership, while enforced through permissions - was not visible where cross-team coordination was required. This led to version conflicts, manual coordination, and unreliable releases.
Intervention: Defined and implemented a shared data lifecycle model that governed how data moved across editing, staging, validation, and release - establishing system-level ownership, visibility, and readiness signals.
- Impact:
- 30% reduction in release errors
- 25% faster staging and validation
- Increased cross-team visibility and alignment
- Reduced manual coordination and operational overhead
Context & Complexity
I led UX for a core workflow within an enterprise automotive platform used by marketing, pricing, and product teams to manage vehicle data prior to release. Each team worked on a shared dataset but operated through independent workflows:
- Multiple teams edited data in parallel
- Changes were staged independently
- A single release required coordination across all teams
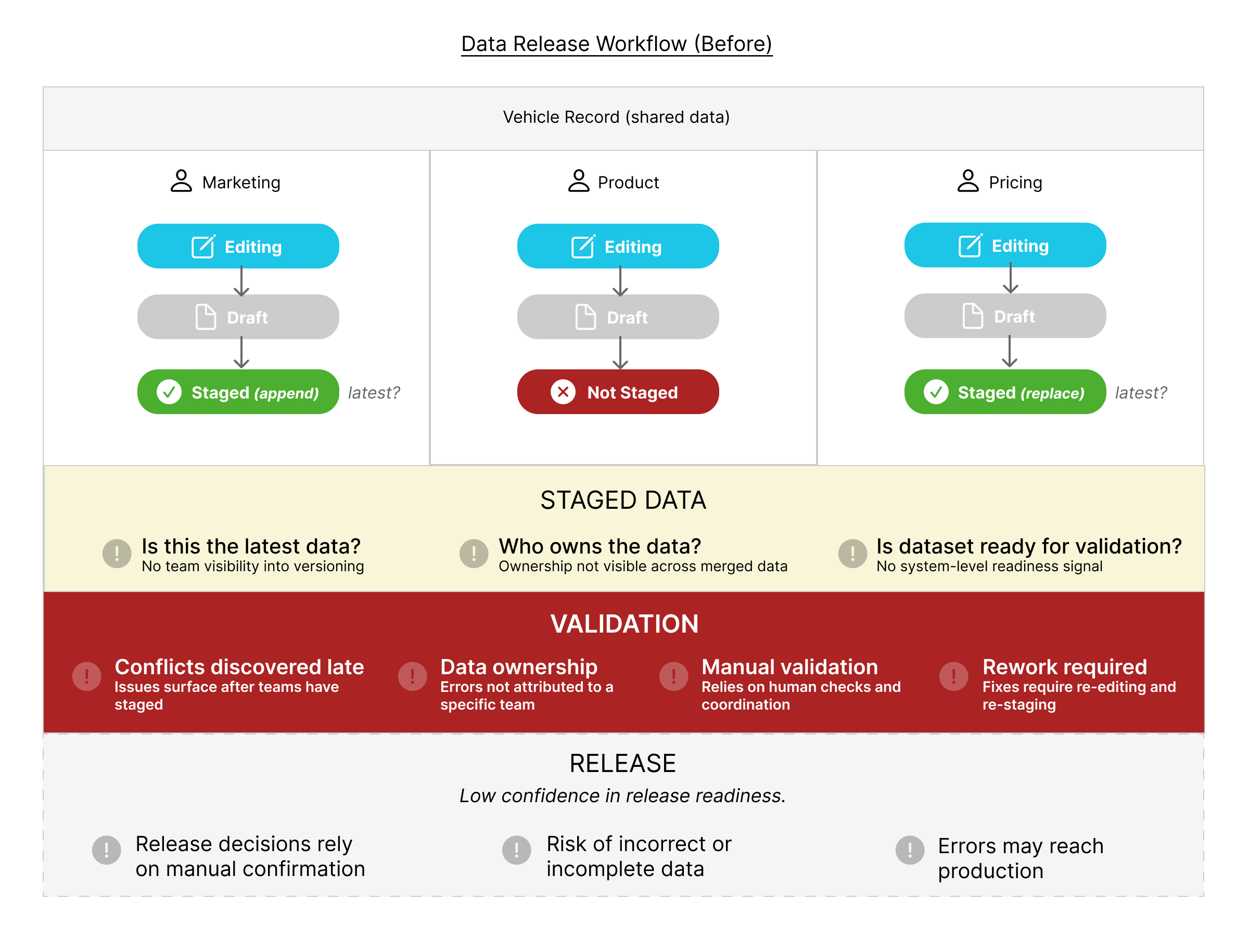
Because these workflows were not connected at a system level, a vehicle record could exist in multiple states simultaneously - partially staged, partially validated, or incomplete. This created significant complexity:
- Version conflicts between staged and unstaged data
- No clear ownership of fields after merges
- Inconsistent staging practices across teams
- Manual, fragmented validation processes
- No clear signal of overall release readiness
While these issues appeared as workflow inefficiencies, the underlying problem was structural - the system had no way to coordinate readiness across teams contributing to a shared release. This created a core tension in the system - balancing team autonomy and speed with the need for coordination and risk management.
Core Problem
The problem was initially framed as a validation issue - errors were being caught late in the release process. Early efforts focused on improving validation through better checks and clearer error handling. However, deeper analysis revealed that validation was not the root cause.
- Teams were staging data independently
- There was no shared visibility into readiness across teams
- A vehicle could exist in multiple conflicting states simultaneously
- Validation was catching issues after coordination had already broken down
Ownership was enforced during editing through permissions, but became unclear once data was merged across teams - particularly in scenarios involving dependencies and partial staging.
This led to a reframing of the problem:
From: Improving validation accuracy
To: Coordinating readiness across multiple teams contributing to a shared release
This shifted the focus from optimizing a step in the workflow to designing a system that could orchestrate behavior across teams and states. I had to define the direction by reframing the problem and aligning product and engineering around a shared system model.
Designing the System Model
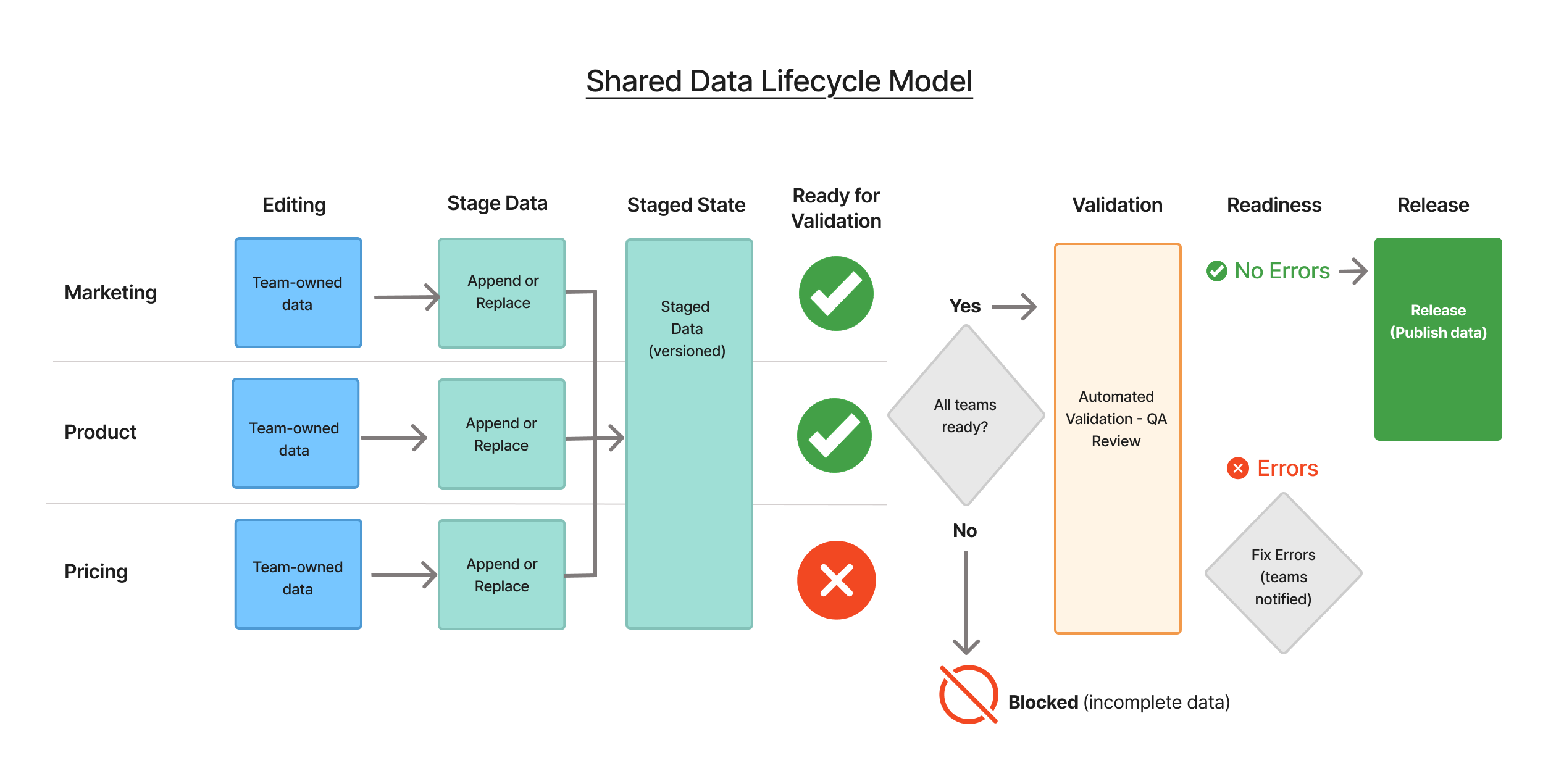
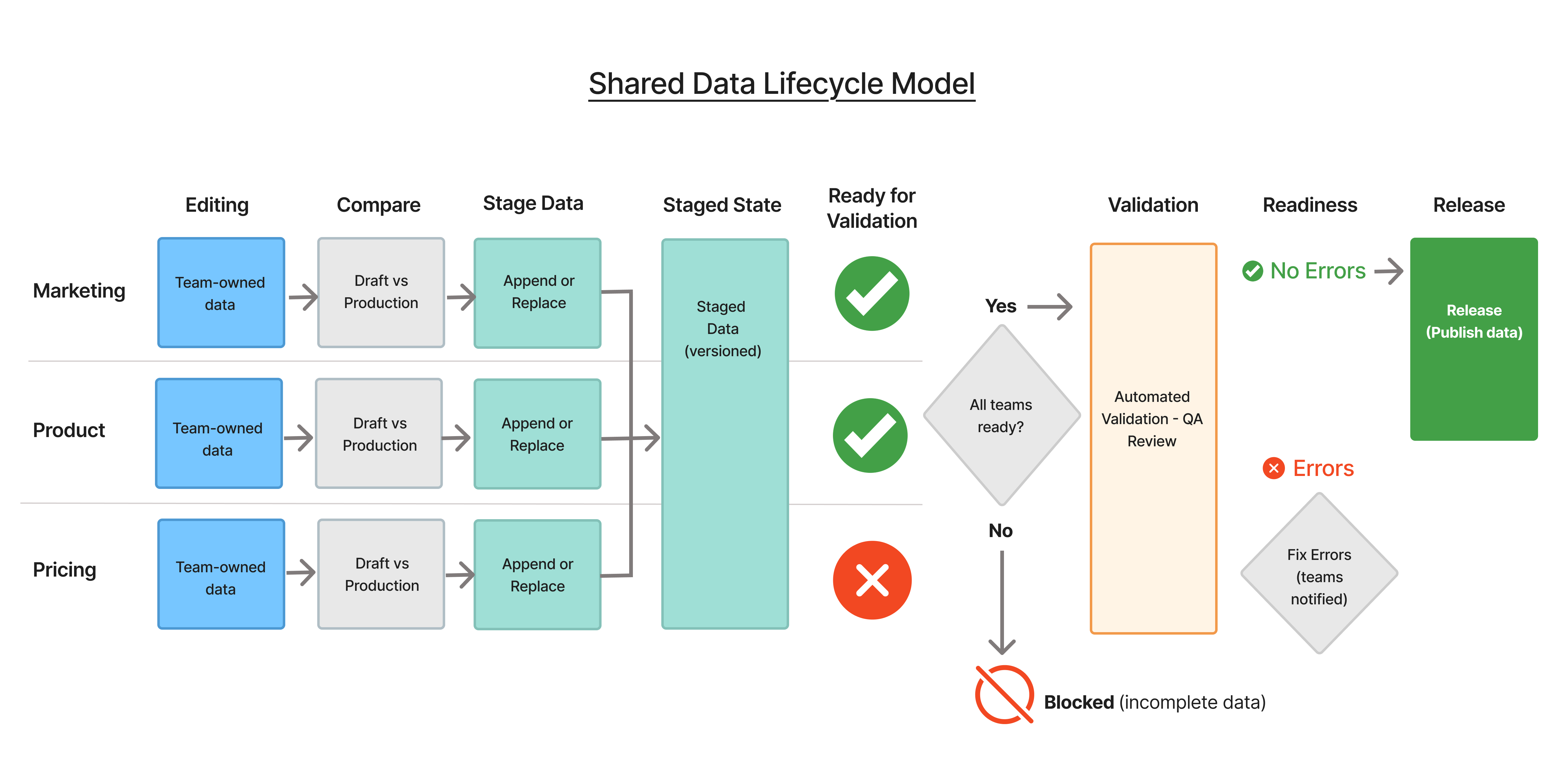
Instead of optimizing individual workflows, I introduced a shared lifecycle model to coordinate system behavior across teams.
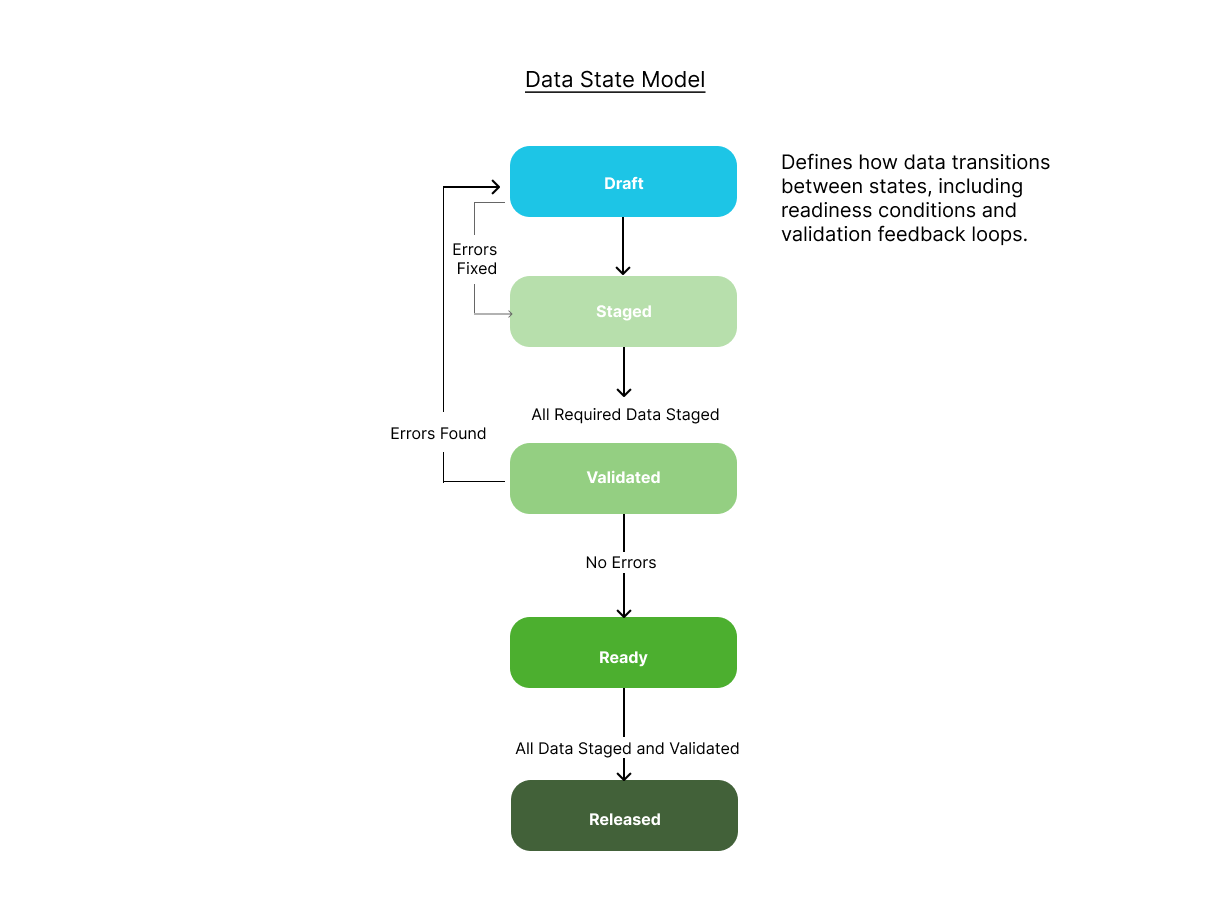
Defined a lifecycle model governing how data moved through the system:
Draft → Staged → Validated → Ready → Released
Automated validation was followed by a QA review step, allowing teams to approve exceptions and ensure data quality before release. This lifecycle became the governing model across the platform.
System Design Principals
I translated the lifecycle model into a set of consistent interaction patterns, balancing system coordination with team flexibility.
- Defined state transitions to make data progression visible from editing through release
- Introduced system-level readiness signals to determine when a dataset was safe to validate
- Made ownership visible at points of coordination, particularly after data was merged
- Identified key breakdowns in coordination, especially at staging and validation
Iterated through whiteboarding, diagramming, and validation with product, engineering and users.
Prototyping the Lifecycle
I used prototyping to validate how the lifecycle model would behave under real-world conditions - particularly where multiple teams contributed to a shared dataset. Rather than focusing on individual UI interactions, I tested system behavior: how data moved through staging, how readiness was determined, and how issues surfaced during validation. Prototyping also served as a tool for alignment, helping product and engineering teams validate how the system should behave under real-world conditions.
Key areas of exploration included:
- When and how data should transition into staging
- How to determine when a full dataset was ready for validation
- How to identify incomplete or conflicting data prior to validation
- How ownership should be surfaced once data was merged across teams
Key Insight:
As we tested the lifecycle with users, a key gap started to emerge - teams were making staging decisions without a clear, shared view of how their changes compared to production. But more importantly, they were already compensating for that - using external methods like spreadsheets to compare changes. Those approaches were inconsistent, time-consuming, and not visible to other teams. So the insight wasn’t that comparison was needed - it was that it was already happening, just outside the system. And that created both risk and a lack of coordination. To address this, I introduced a comparison step before staging, evolving the lifecycle to:
Draf → Compare → Staged → Validated → Ready → Released
This introduced some initial friction, as teams were concerned it would slow down their workflow. Many were already using external methods, such as spreadsheets, to compare changes - but these approaches were inconsistent and not visible within the system.
By integrating comparison directly into the workflow, I was able to reduce that friction while making the process consistent, trackable, and easier to act on.
Updated Lifecycle Model
Designing The Experience
I translated the lifecycle model into a set of consistent interaction patterns across the platform.
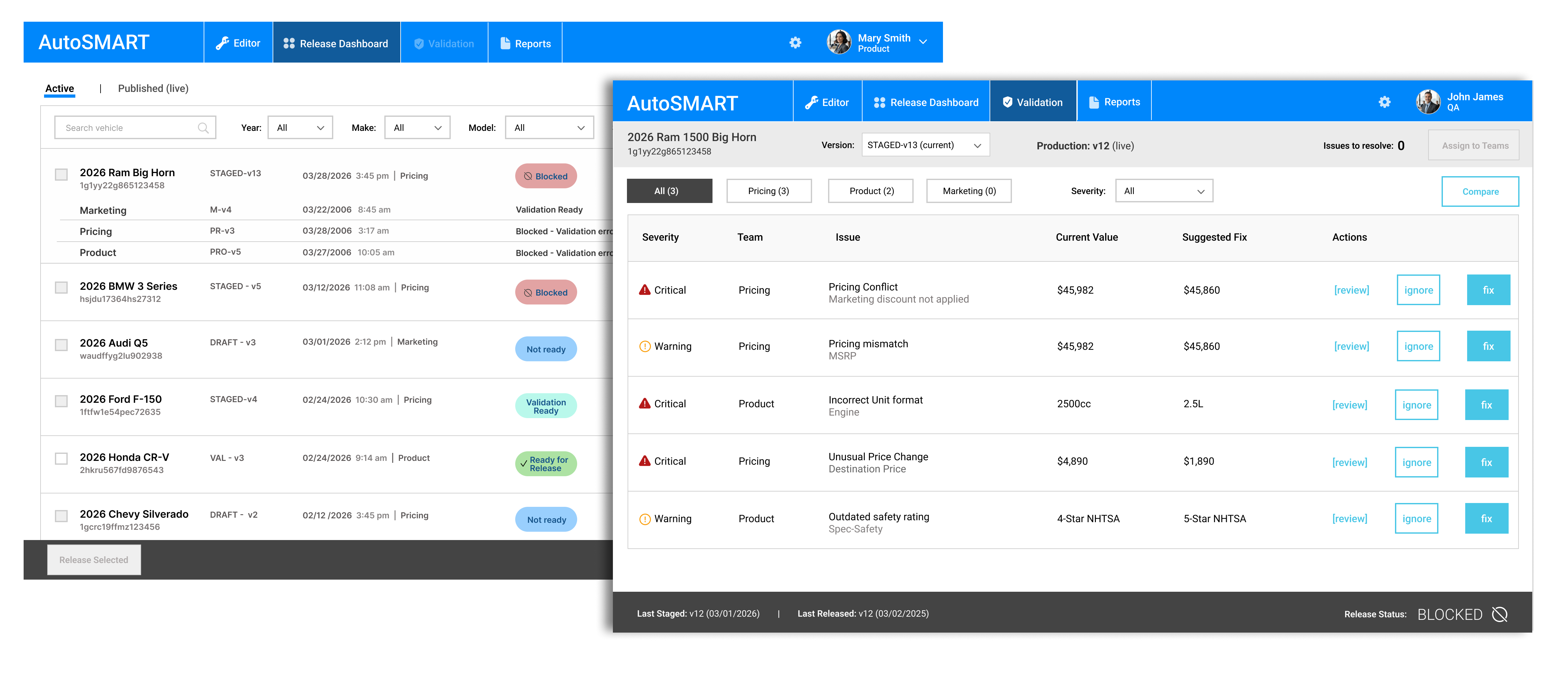
Release Dashboard
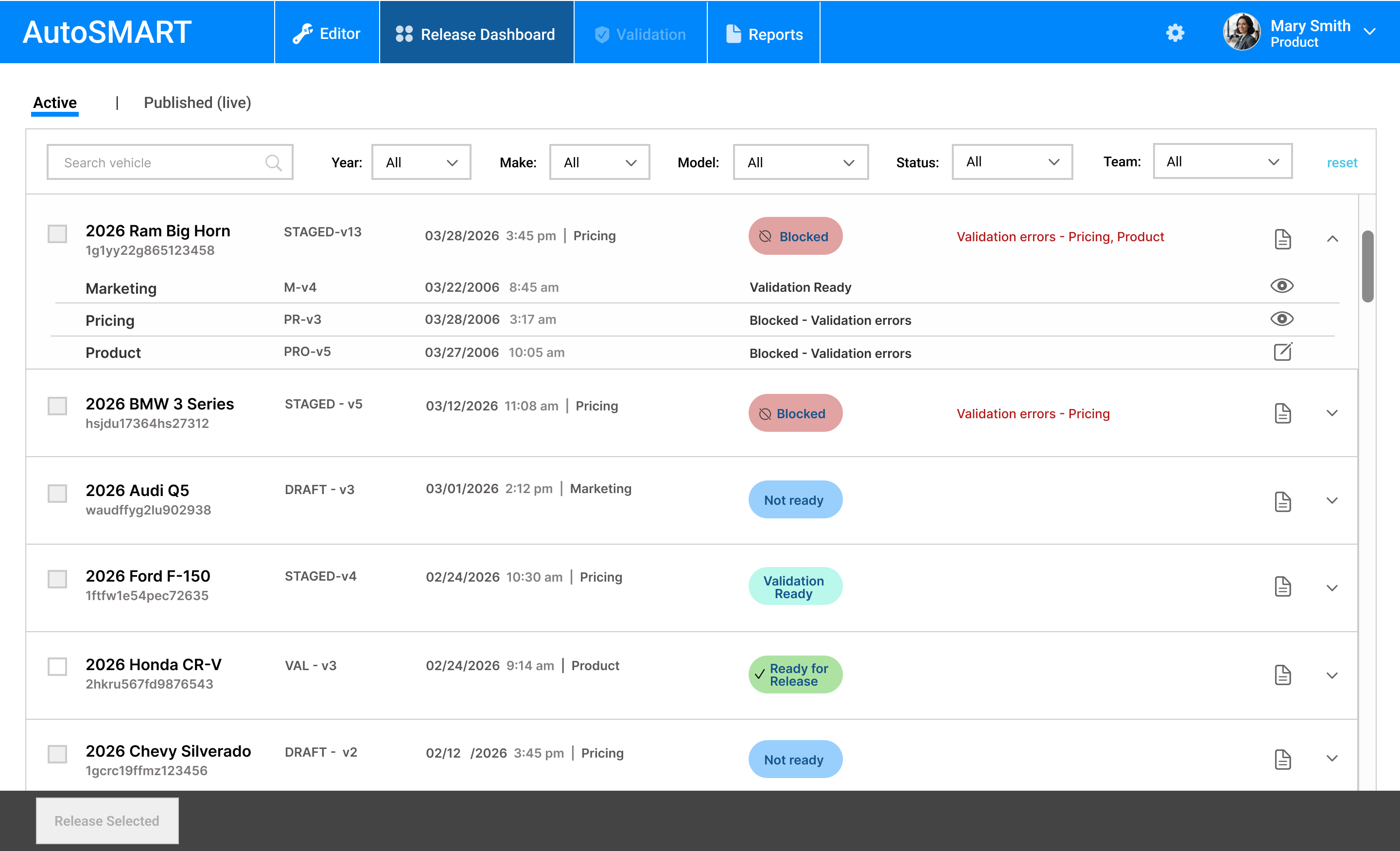
- Surfaced system-level readiness states (Not Ready, Blocked, Ready for Release) to reflect overall dataset status
- Enabled expansion into team-level views to show ownership and contribution across marketing, pricing, and product
- Highlighted blocking issues and responsible teams directly in the workflow
- Supported filtering by team to allow users to quickly identify items requiring their action
This approach provided system-level visibility without overwhelming users, using progressive disclosure to balance clarity with usability.
Editor
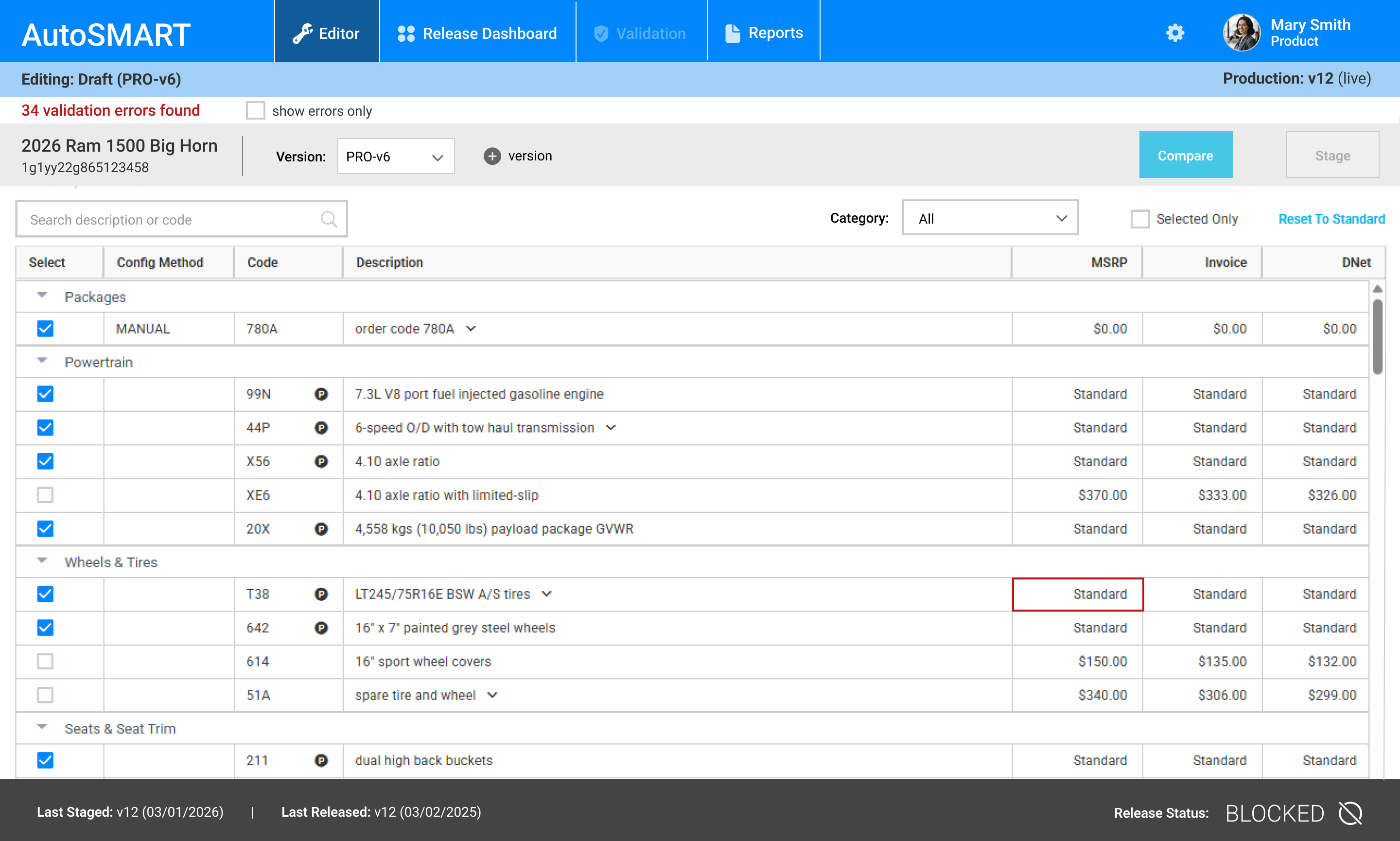
- Supported team-level versioning, allowing users to work on draft versions (e.g., PROD-v6) while maintaining visibility into the live production dataset
- Surfaced validation issues directly within the editing workflow, including a running error count and field-level highlighting to support fast resolution
- Enabled a fix - re-stage workflow, allowing users to resolve validation errors and stage updates without re-running comparison against production
- Maintained clear system context, showing draft state alongside the current production version to reduce errors during editing
- Provided controlled progression through actions (Compare, Stage), ensuring changes were validated before moving forward
Rather than restricting editing to prevent conflicts, I supported parallel work while managing risk through visibility, validation, and controlled progression.
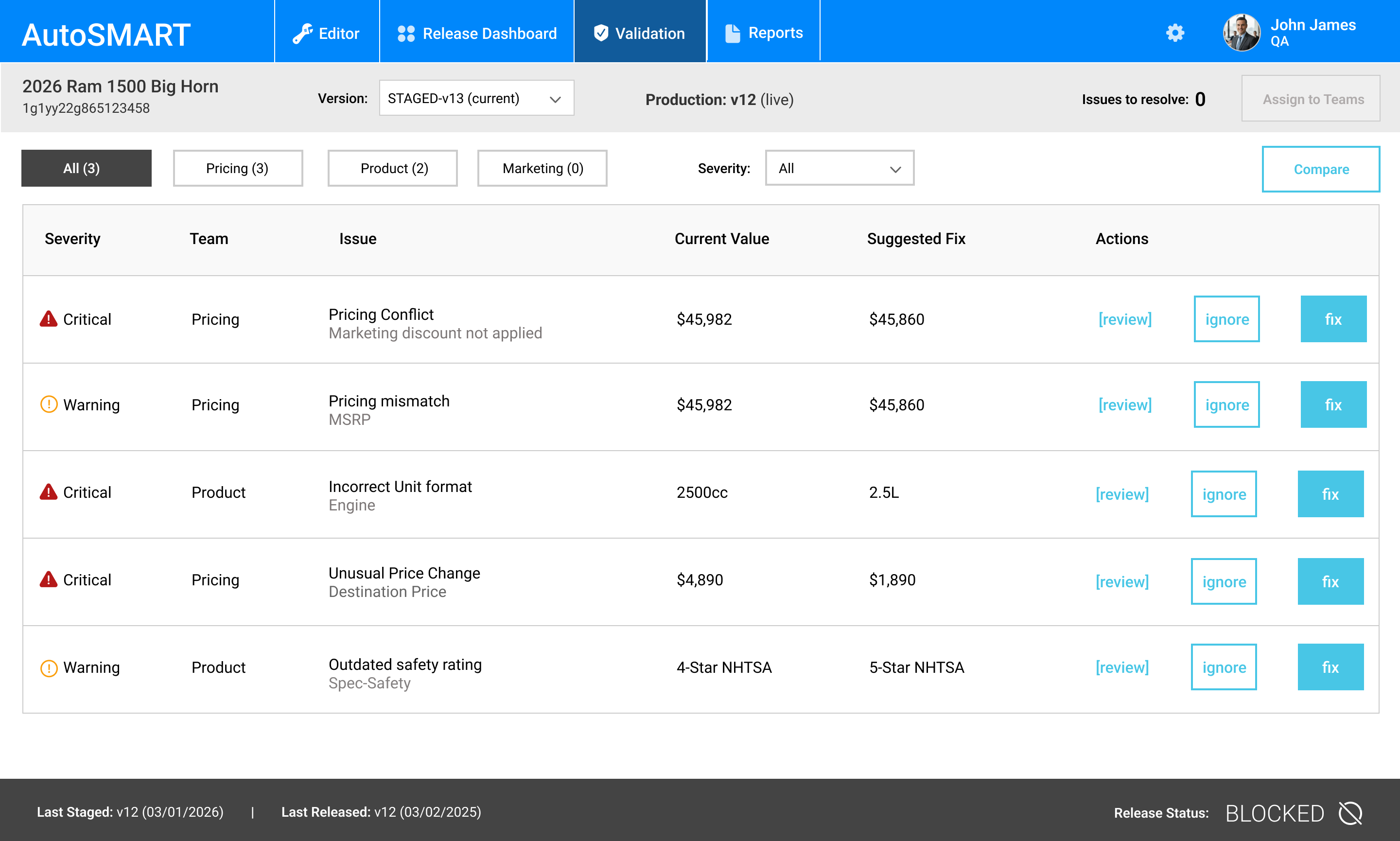
Validation Experience
Validation was a critical point in the lifecycle, where data quality and readiness were determined before release. I designed the validation experience to surface issues clearly and support efficient resolution across teams.
- Aggregated validation results at the dataset level to provide a clear readiness signal
- Highlighted errors by severity and ownership to support coordinated resolution
- Enabled drill-down into field-level issues directly from validation summaries
- Supported a fix → re-stage workflow, allowing teams to resolve issues without restarting the process
To improve efficiency and reduce manual effort, I explored AI-assisted validation:
- Surfaced anomalies and inconsistencies that may not be captured by rule-based checks
- Helped prioritize issues based on potential impact
- Provided context to support faster decision-making
AI was used to augment validation rather than replace it, maintaining human oversight and trust in the system.
Validation and Testing
Given the complexity of parallel workflows, I focused testing on reducing risk at key breakdown points - particularly around staging completeness, readiness determination, and validation timing. Rather than validating individual screens, testing focused on system behavior under real-world conditions, using scenario-based workflows that simulated multiple teams contributing to a shared dataset. This included:
- Testing how users determined when a dataset was ready for validation
- Evaluating how incomplete, conflicting, or outdated data was identified prior to validation
- Assessing whether ownership was clear once data was merged across teams
- Validating whether feedback supported fast and accurate issue resolution
- Measuring user confidence in system-driven readiness versus manual coordination
Impact
- 30% reduction in release errors
- 25% faster workflows
- Increased cross-team visibility and alignment
- Reduced manual coordination and operational overhead
- Improved downstream data quality
Beyond performance improvements, the introduction of a shared lifecycle model introduced a shared coordination model that improved predictability, reduced ambiguity, and created a foundation for future system evolution.